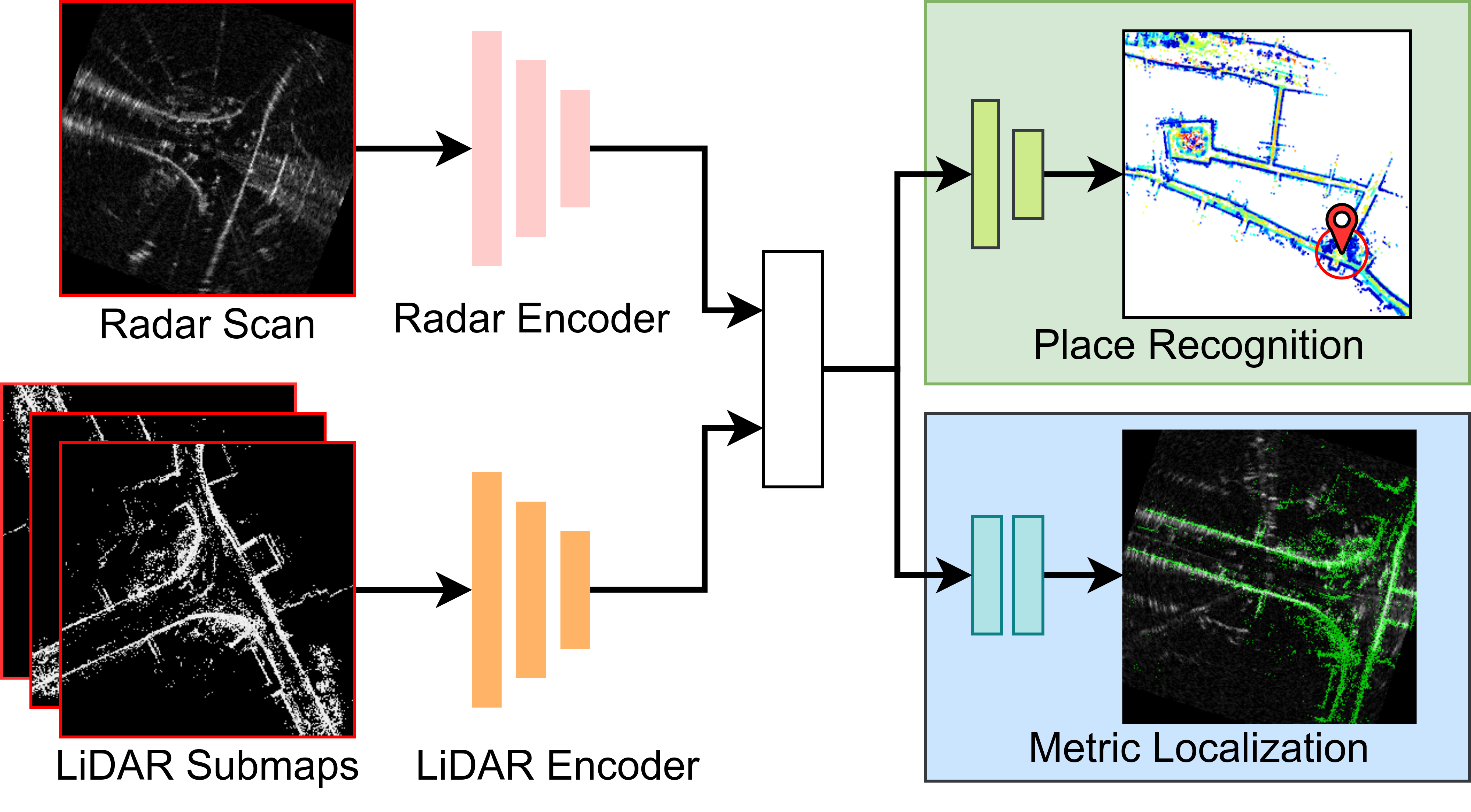
Differently from existing radar-LiDAR localization methods, RaLF is the first method to jointly address both place recognition and metric localization. We reformulate the metric localization task as a flow estimation problem, where we aim at predicting pixel-level correspondences between the radar and LiDAR samples, which are subsequently used to estimate a 3-DoF transformation. For place recognition, we leverage a combination of same-modal and cross-modal metric learning to learn a shared embedding space where features from both modalities can be compared against each other.
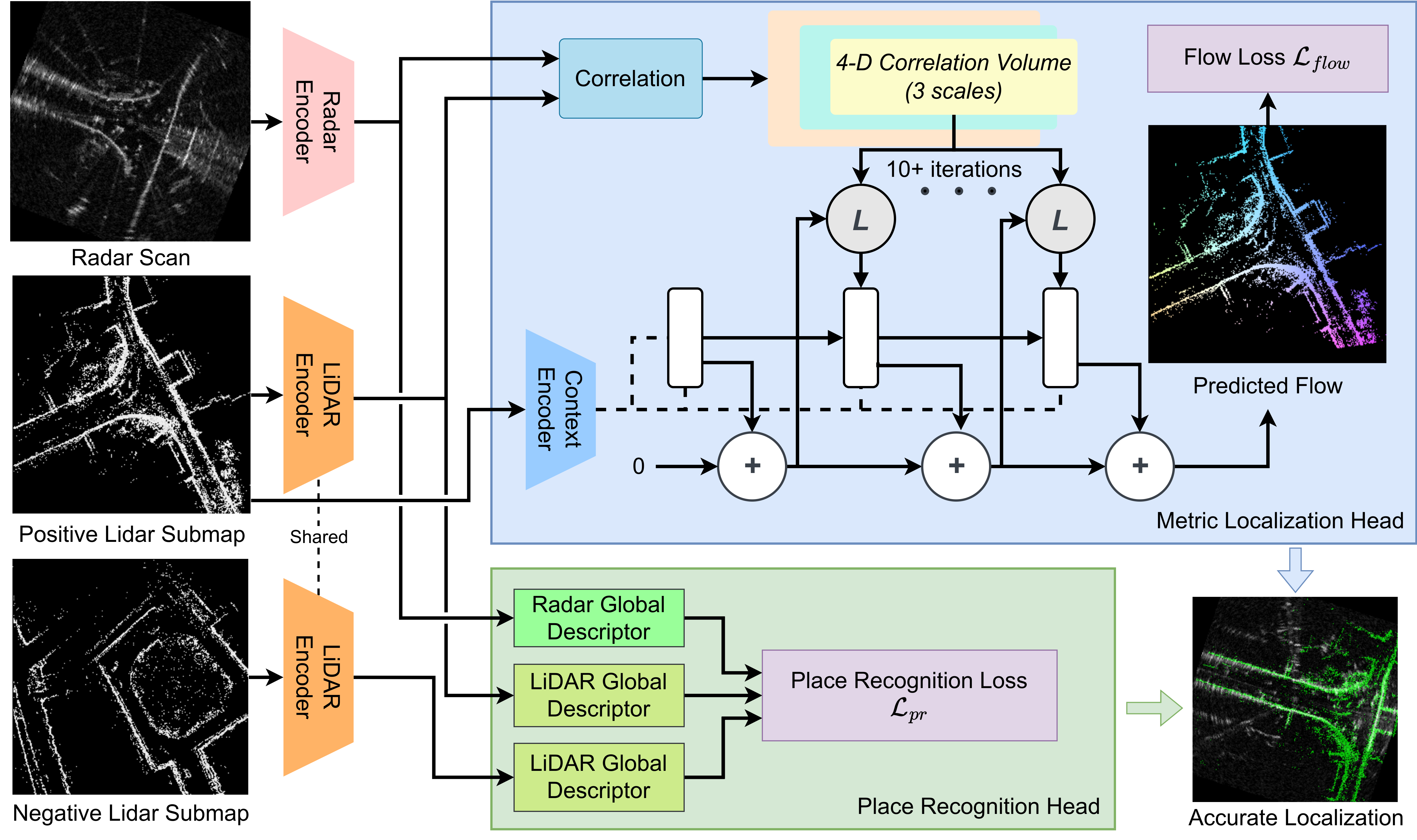
The architecture of the two encoders, namely the radar encoder and LiDAR encoder, is based on the feature encoder of RAFT, which consists of a convolutional layer with stride equal to two, followed by six residual layers with downsampling after the second and fourth layer. Differently from the original feature encoder of RAFT which shares weights between the two input images, RaLF employs separate feature extractors for each modality due to the distinct nature of radar and LiDAR data.
The place recognition head has a twofold purpose: firstly, it aggregates the feature maps from the feature extractor into a global descriptor. Secondly, it maps features from radar and LiDAR data, which naturally lie in different embedding spaces, into a shared embedding space, where global descriptors of radar scans and LiDAR submaps can be compared against each other. The architecture of the place recognition head is a shallow CNN composed of four convolutional layers with feature sizes (256, 128, 128, 128), respectively. Each convolutional layer is followed by batch normalization and ReLU activation. Differently from the feature encoders, the place recognition head is shared between the radar and LiDAR modalities. To train the place recognition head, we use the well-known triplet technique, where triplets composed of (anchor, positive, negative) samples are selected to compute the triplet loss. The positive sample is a BEV image depicting the same place as the anchor sample, while the negative sample is a BEV image of a different place. While typically this technique is employed to compare triplets of samples of the same modality, in our case the samples can be generated from different modalities.
For metric localization of radar scans against a LiDAR map, we propose to learn pixel-wise matches in the form of flow vectors. The intuition behind this decision is that a radar BEV image and a LiDAR BEV image taken at the same position should be well aligned. Therefore, for every pixel in the LiDAR BEV image, our metric localization head predicts the corresponding pixel in the radar BEV image. The architecture of our metric localization head is based on RAFT, which first computes a 4-D correlation volume between the features extracted by the two encoders. The correlation volume is then fed into a GRU that iteratively refines the estimated flow map.
During inference, given a query radar scan, we first compute its global descriptor, and we compare it against all the submap descriptors. We then select the submap with the highest similarity. We then feed the radar scan and the selected submap to the metric localization head, which outputs a flow map, which we use to estimate the 3-DoF transformation between the radar scan and the LiDAR map using RANSAC.